다음은 대한민국 영화 중에서 관객 수가 가장 많은 상위 8개의 데이터이다.
주어진 코드를 이용하여 퀴즈를 풀어보시오.
import pandas as pdimport matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family'] = 'Malgun Gothic'
matplotlib.rcParams['font.size'] = 15
matplotlib.rcParams['axes.unicode_minus'] = Falsedata = {
'영화' : ['명량', '극한직업', '신과함께-죄와 벌', '국제시장', '괴물', '도둑들', '7번방의 선물', '암살'],
'개봉 연도' : [2014, 2019, 2017, 2014, 2006, 2012, 2013, 2015],
'관객 수' : [1761, 1626, 1441, 1426, 1301, 1298, 1281, 1270], # (단위 : 만 명)
'평점' : [8.88, 9.20, 8.73, 9.16, 8.62, 7.64, 8.83, 9.10]
}
df = pd.DataFrame(data)
df
1. 영화 데이터를 활용하여 x축은 영화, y축은 평점인 막대 그래프를 만드시오.
plt.bar(df['영화'], df['평점'])
2. 앞에서 만든 막대 그래프에 제시된 세부사항을 적용하시오
* 제목 : 국내 Top 8 영화 평점 정보
* x축 label : 영화 (90도 회전)
* y축 label : 평점
plt.bar(df['영화'], df['평점'])
plt.title('국내 Top 8 영화 평점 정보')
plt.xlabel('영화')
plt.xticks(rotation = 90)
plt.ylabel('평점')
plt.show()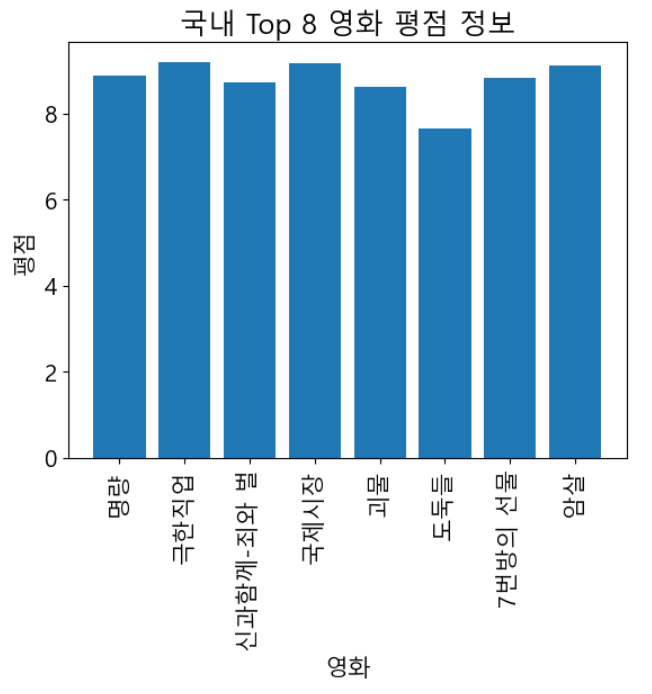
3. 개봉 연도별 평점 변화 추이를 꺾은선 그래프로 그리시오¶
df_group = df.groupby('개봉 연도').mean(numeric_only=True)
df_group
plt.plot(df_group.index, df_group['평점'])
4. 앞에서 만든 그래프에 제시된 세부 사항을 적용하세요
* marker = 'o'
* x축 눈금 : 5년 단위 (2005, 2010, 2015, 2020)
* y축 범위 : 최소 7, 최대 10
plt.plot(df_group.index, df_group['평점'], marker = 'o')
plt.ylim(7,11)
plt.xticks([2005, 2010, 2015, 2020])
plt.show()
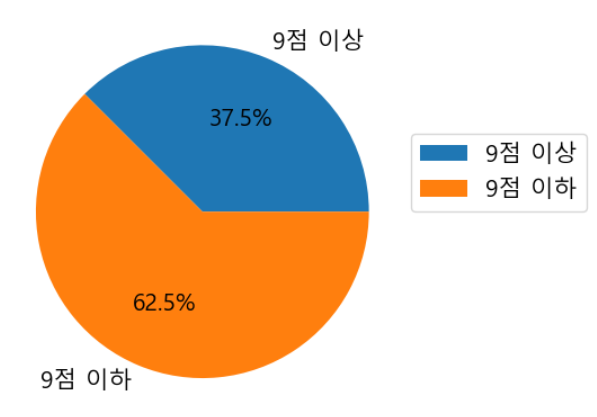
5. 평점이 9점 이상인 영화의 비율을 확인할 수 있는 원 그래프를 제시된 세부사항을 적용하여 그리시오
* label : 9점 이상 / 9점 미만
* 퍼센트 : 소수점 첫째 자리까지 표시
* 범례 : 그래프 우측에 표시
filt = df['평점'] >= 9.0
df[filt]
values = [len(df[filt]), len(df[~filt])]
labels = ['9점 이상', '9점 이하']plt.pie(values, labels = labels, autopct = '%.1f%%')
plt.legend(loc=(1,0.5))